Hoje quero falar com vocês sobre Maturidade no Uso de IA.
Não, não no contexto de Legal & Compliance, mas, sim, em um contexto de Escala de Maturidade.
Se imaginássemos que a Jornada de IA de uma empresa ou indivíduo fosse uma escada, quais seriam os degraus iniciais? Qual seria o topo dela?
Vem comigo:
A maioria das pessoas mede sua maturidade em IA pelas ferramentas que utiliza.
Eu acredito que esse é apenas o começo.
Na prática, a evolução acontece quando a IA passa a transformar a forma como trabalhamos.
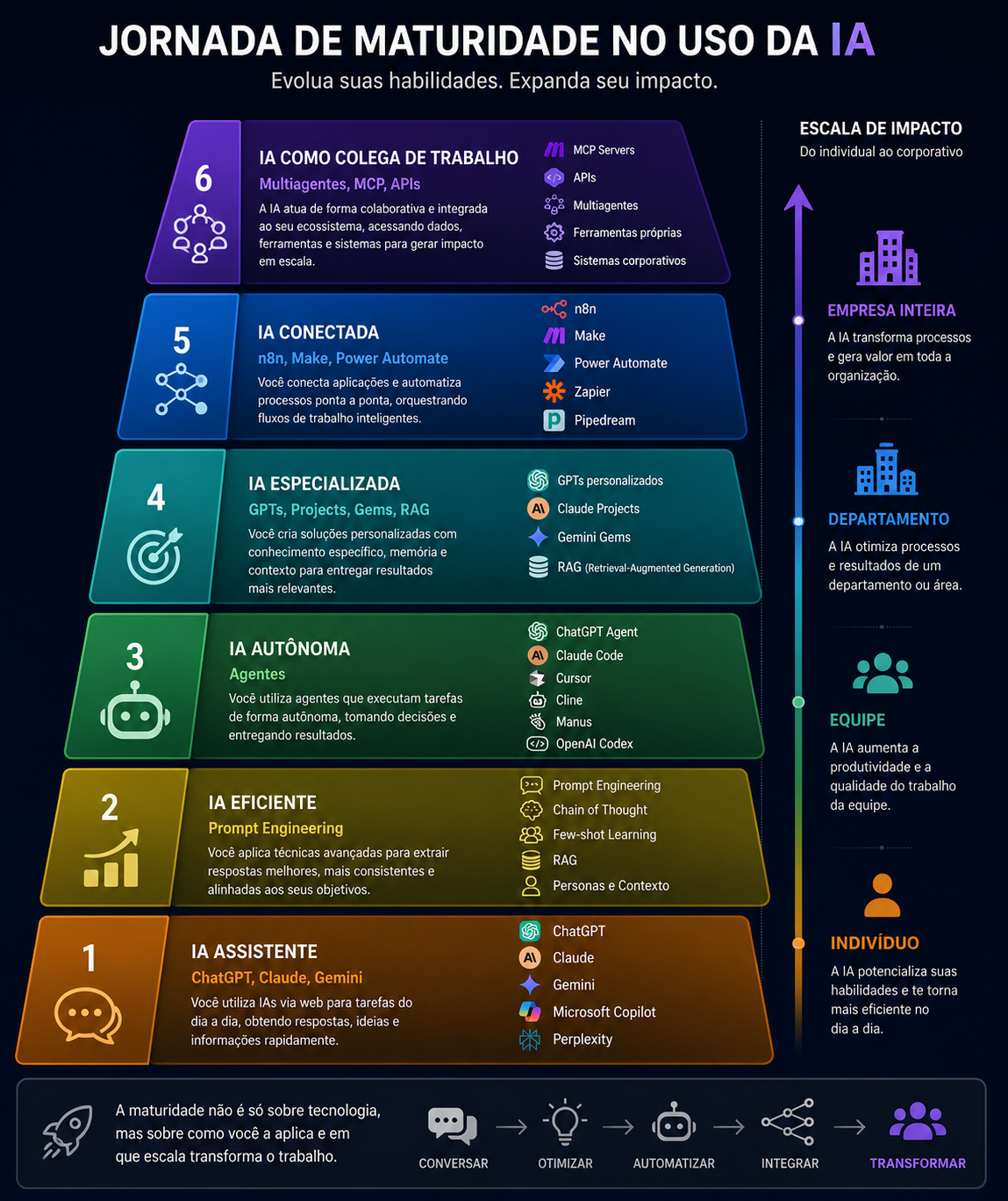
É uma jornada de maturidade que (hoje) enxergo como possuindo seis níveis (este trabalho ainda está em construção):
1️⃣ IA Assistente
ChatGPT, Claude, Gemini… A IA ajuda a executar tarefas do dia a dia.
2️⃣ IA Eficiente
Prompt Engineering e técnicas avançadas permitem extrair respostas muito melhores e mais consistentes.
3️⃣ IA Autônoma
Agentes começam a executar tarefas completas, reduzindo trabalho manual e acelerando entregas.
4️⃣ IA Especialista
GPTs personalizados, Projects, Gems e RAG tornam a IA especialista no seu contexto e no conhecimento da sua organização.
5️⃣ IA Conectada
Ferramentas como n8n, Make e Power Automate conectam sistemas e automatizam processos de ponta a ponta.
6️⃣ IA como Colega de Trabalho
Multiagentes, MCP e APIs permitem que a IA trabalhe integrada ao ecossistema da empresa, colaborando com pessoas e outros sistemas para gerar valor em escala.
Mas existe uma segunda dimensão que considero ainda mais importante.
A maturidade não depende apenas da tecnologia utilizada, e sim da escala do impacto que ela gera:
👤 Indivíduo → melhora sua produtividade.
👥 Equipe → acelera a colaboração.
🏢 Departamento → transforma processos.
🏭 Empresa inteira → cria novas vantagens competitivas.
Em outras palavras, não é sobre a tecnologia usada.
É sobre o impacto que ela gera no negócio.
E a maturidade não é sobre a complexidade da tecnologia usada. É sobre a maturidade da liderança em construir sistemas de gestão e inovação neste novo cenário.