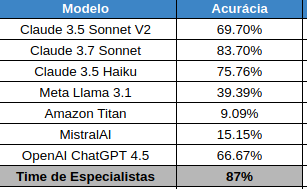
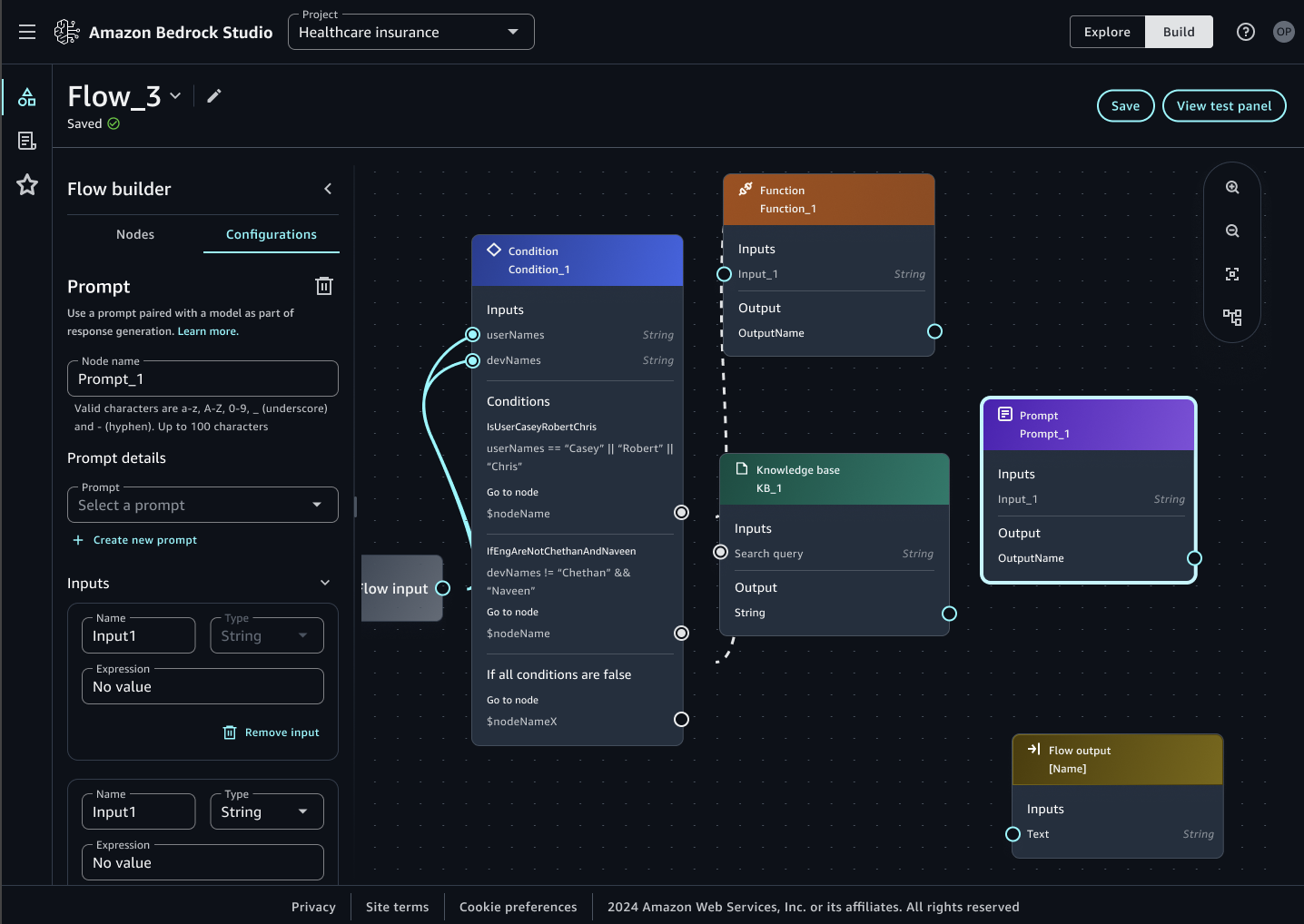
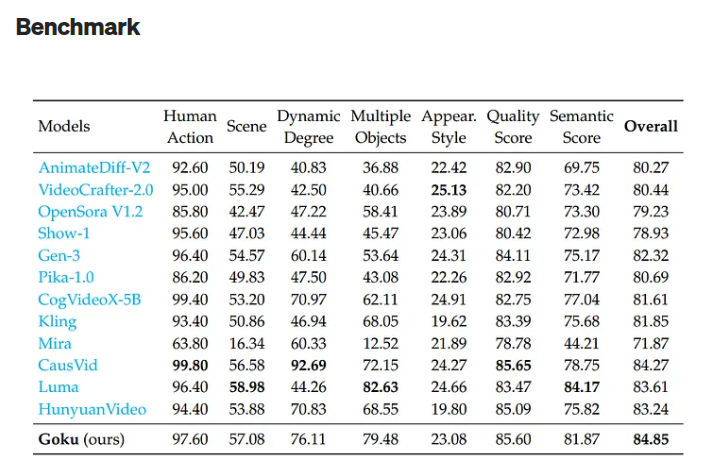
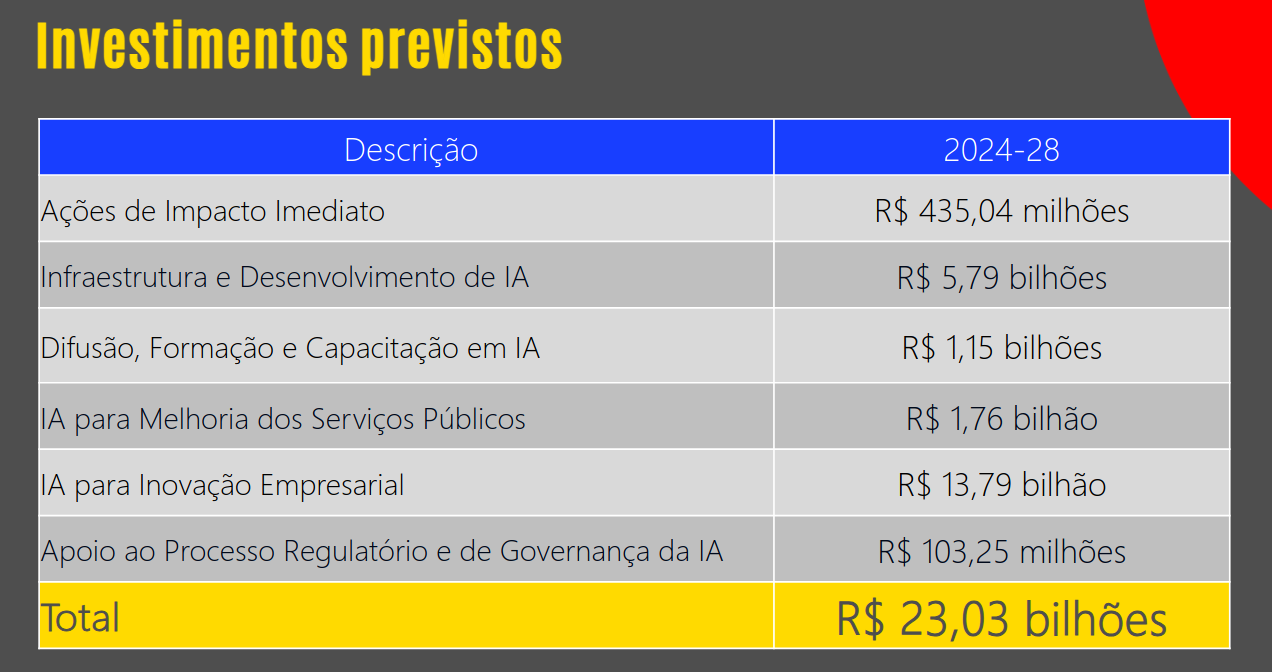
🏬 O memo do CEO da Shopify vai dar o que falar nas próximas semanas. Concordo com a filosofia e acho que aponta um caminho a ser seguido.
Seguem os pontos principais do memo:
1. Utilizar a IA de forma eficaz é agora uma expectativa fundamental para todos na Shopify. Hoje, ela é uma ferramenta para todas as áreas e só vai se tornar mais importante. Francamente, não acho viável optar por não aprender a aplicar IA na sua área de atuação; você pode tentar, mas quero ser honesto: não vejo isso funcionando hoje, e com certeza não funcionará no futuro. A estagnação é quase certa — e estagnação é um fracasso em câmera lenta. Se você não está subindo, está escorregando.
2. A IA deve fazer parte da fase de prototipagem do GSD. A fase de protótipo de qualquer projeto GSD deve ser dominada pela exploração com IA. Prototipar serve para aprender e gerar informação. A IA acelera esse processo de forma dramática. Você pode aprender a produzir algo que outros colegas consigam analisar, utilizar e compreender em uma fração do tempo que costumava levar.
3. Adicionaremos perguntas sobre o uso de IA aos nossos questionários de avaliação de desempenho e revisão entre pares. Aprender a usar IA bem é uma habilidade nada óbvia. Minha percepção é que muitas pessoas desistem após escrever um prompt e não receber exatamente o que esperavam. Aprender a criar prompts e carregar o contexto corretamente é importante, e obter feedback dos colegas sobre como isso está indo será valioso.
4. O aprendizado é autodirigido, mas compartilhe o que você aprender. Você tem acesso ao máximo de ferramentas de IA de ponta possível. Temos o chat.shopify.io há anos. Desenvolvedores têm acesso ao Proxy, Copilot, Cursor, Claude Code — tudo pré-configurado e pronto para uso. Vamos aprender e nos adaptar juntos, como um time. Vamos compartilhar conquistas (e tropeços!) uns com os outros enquanto experimentamos novas capacidades de IA, e vamos dedicar tempo para integração da IA nas nossas análises mensais de negócios e ciclos de desenvolvimento de produto. O Slack e o Vault têm muitos espaços onde as pessoas compartilham os prompts que criaram, como os canais #revenue-ai-use-cases e #ai-centaurs.
5. Antes de solicitar mais pessoas ou recursos, os times devem demonstrar por que não conseguem realizar o que precisam com o uso de IA. Como seria essa área se agentes autônomos de IA já fizessem parte da equipe? Essa pergunta pode levar a discussões e projetos muito interessantes.
6. “Todos” significa todos. Isso se aplica a todos nós — incluindo a mim e à equipe executiva.