Aplicamos IA para desbloquear valor, potencializar vantagens competitivas e criar novas oportunidades de negócio.

Automação Inteligente
Automatize processos, reduza tarefas repetitivas e transforme operações com IA aplicada ao negócio.
Transformamos dados em decisões estratégicas, combinando Inteligência Artificial, Analytics e Inovação para acelerar resultados.
Aplicamos IA para desbloquear valor, potencializar vantagens competitivas e criar novas oportunidades de negócio.
Automatize processos, reduza tarefas repetitivas e transforme operações com IA aplicada ao negócio.

Transforme dados em insights claros para decisões mais rápidas e inteligentes com nosso processo I2A2.

Data Lakes, Lakehouses, Pipelines e plataformas escaláveis para sustentar crescimento e inovação.
O que nossos clientes dizem sobre nós:

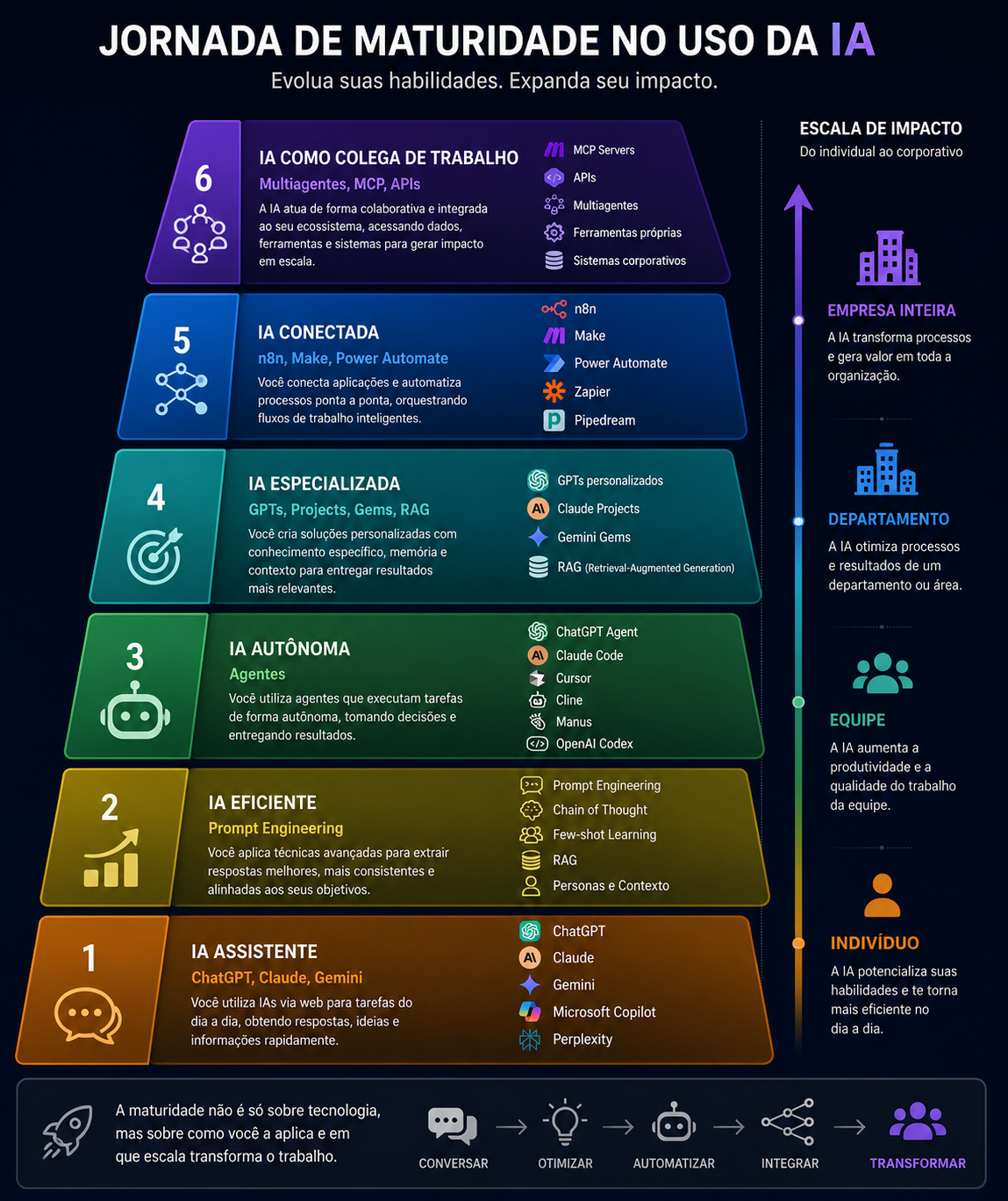
Hoje quero falar com vocês sobre Maturidade no Uso de IA.
Não, não no contexto de Legal & Compliance, mas, sim, em um contexto de Escala de Maturidade.
Se imaginássemos que a Jornada de IA de uma empresa ou indivíduo fosse uma escada, quais seriam os degraus iniciais? Qual seria o topo dela?
Vem comigo:
A maioria das pessoas mede sua maturidade em IA pelas ferramentas que utiliza.
Eu acredito que esse é apenas o começo.
Na prática, a evolução acontece quando a IA passa a transformar a forma como trabalhamos.
É uma jornada de maturidade que (hoje) enxergo como possuindo seis níveis (este trabalho ainda está em construção):
1️⃣ IA Assistente
ChatGPT, Claude, Gemini… A IA ajuda a executar tarefas do dia a dia.
2️⃣ IA Eficiente
Prompt Engineering e técnicas avançadas permitem extrair respostas muito melhores e mais consistentes.
3️⃣ IA Autônoma
Agentes começam a executar tarefas completas, reduzindo trabalho manual e acelerando entregas.
4️⃣ IA Especialista
GPTs personalizados, Projects, Gems e RAG tornam a IA especialista no seu contexto e no conhecimento da sua organização.
5️⃣ IA Conectada
Ferramentas como n8n, Make e Power Automate conectam sistemas e automatizam processos de ponta a ponta.
6️⃣ IA como Colega de Trabalho
Multiagentes, MCP e APIs permitem que a IA trabalhe integrada ao ecossistema da empresa, colaborando com pessoas e outros sistemas para gerar valor em escala.
Mas existe uma segunda dimensão que considero ainda mais importante.
A maturidade não depende apenas da tecnologia utilizada, e sim da escala do impacto que ela gera:
👤 Indivíduo → melhora sua produtividade.
👥 Equipe → acelera a colaboração.
🏢 Departamento → transforma processos.
🏭 Empresa inteira → cria novas vantagens competitivas.
Em outras palavras, não é sobre a tecnologia usada.
É sobre o impacto que ela gera no negócio.
E a maturidade não é sobre a complexidade da tecnologia usada. É sobre a maturidade da liderança em construir sistemas de gestão e inovação neste novo cenário.

A IA que traz resultados não tem glamour.
Já reparou como toda feira de inovação dá um jeito de conseguir um robô humanóide (ou até “cachorróide” rs) para ficar andando pelos corredores?
Isso acontece porque é uma maneira midiática de tangibilizar a inovação. Pega bem nos stories e nos tiktoks.
Mas a IA que traz resultados, aquela que mexe o ponteiro no fim do dia, é zero glamour.
Entender o fluxo de valor do cliente, [re]desenhar processos, remover gargalos, integrar sistemas, desbloquear valor: estas são apenas algumas das atividades que de fato trazem retorno sobre o investimento, mas não ganham tantos likes nas social medias.
E, embora tudo isso possa ser feito 100% remotamente, ainda acredito muito na sinergia do trabalho conjunto, presencial, no olho-no-olho.
Porque aqui na Máquina de Dados não endeusamos a maximização do uso de tokens, preferimos maximar a sola de sapato gasta para que você possa maximizar o seu retorno sobre o investimento.
Aproveito para agradecer aos clientes e parceiros que estão conosco nesta jornada. Deixo abaixo alguns registros dessas últimas semanas.

Há 20 anos eu comecei minha jornada trabalhando com Dados.
Naquela época, Inteligência Artificial parecia algo distante. Big Data ainda nem era um termo popular. E convencer empresas de que dados poderiam apoiar decisões estratégicas já era, por si só, um enorme desafio.
De lá pra cá, a tecnologia mudou completamente.
Mudaram as ferramentas, as arquiteturas, as linguagens, a velocidade das transformações e até a forma como trabalhamos.
Mas uma coisa nunca mudou: no fim, trabalhar com Dados nunca foi sobre dados.
Sempre foi sobre pessoas.
Sobre ajudar organizações a enxergarem melhor seus desafios. Sobre transformar complexidade em clareza.
Sobre apoiar decisões mais inteligentes, humanas e conscientes.
Neste mês, a Máquina de Dados completa 9 anos. E eu completo 20 anos atuando na área de Dados, BI, Big Data e IA.
Esse carrossel reúne algumas das reflexões, aprendizados e provocações que marcaram essa trajetória.
Obrigado a todos os clientes, parceiros, amigos, alunos e equipes que fizeram parte dessa caminhada até aqui.
E, principalmente, obrigado por acreditarem que tecnologia só faz sentido quando ajuda pessoas a construírem futuros melhores.