💡 O que é o “Goku”?
O Goku, cujo nome oficial é OmniHuman-1, é um novo modelo multimodal de IA da ByteDance baseado na arquitetura “Rectified Transformer Flow” de aprendizado de máquina profundo, utilizada na maioria dos modelos de difusão modernos para gerar imagens a partir de prompts multimodais.
A maior vantagem dessa arquitetura em relação a transformadores anteriores é que, além de combinar geração integrada de vídeos e imagens, ela possibilita um aprendizado intermodal nos processos de treinamento.
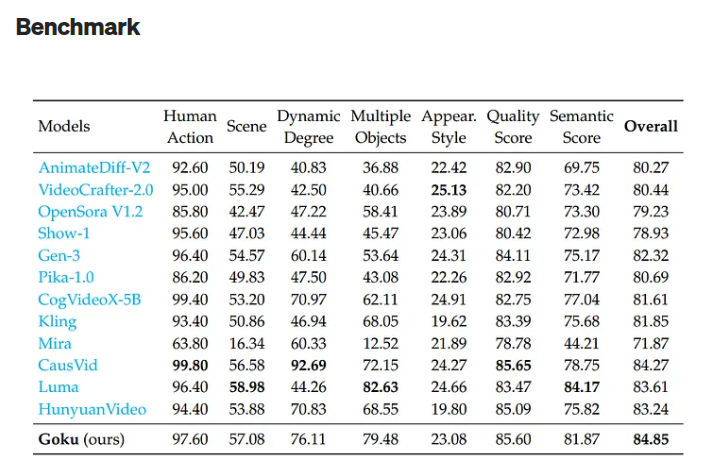
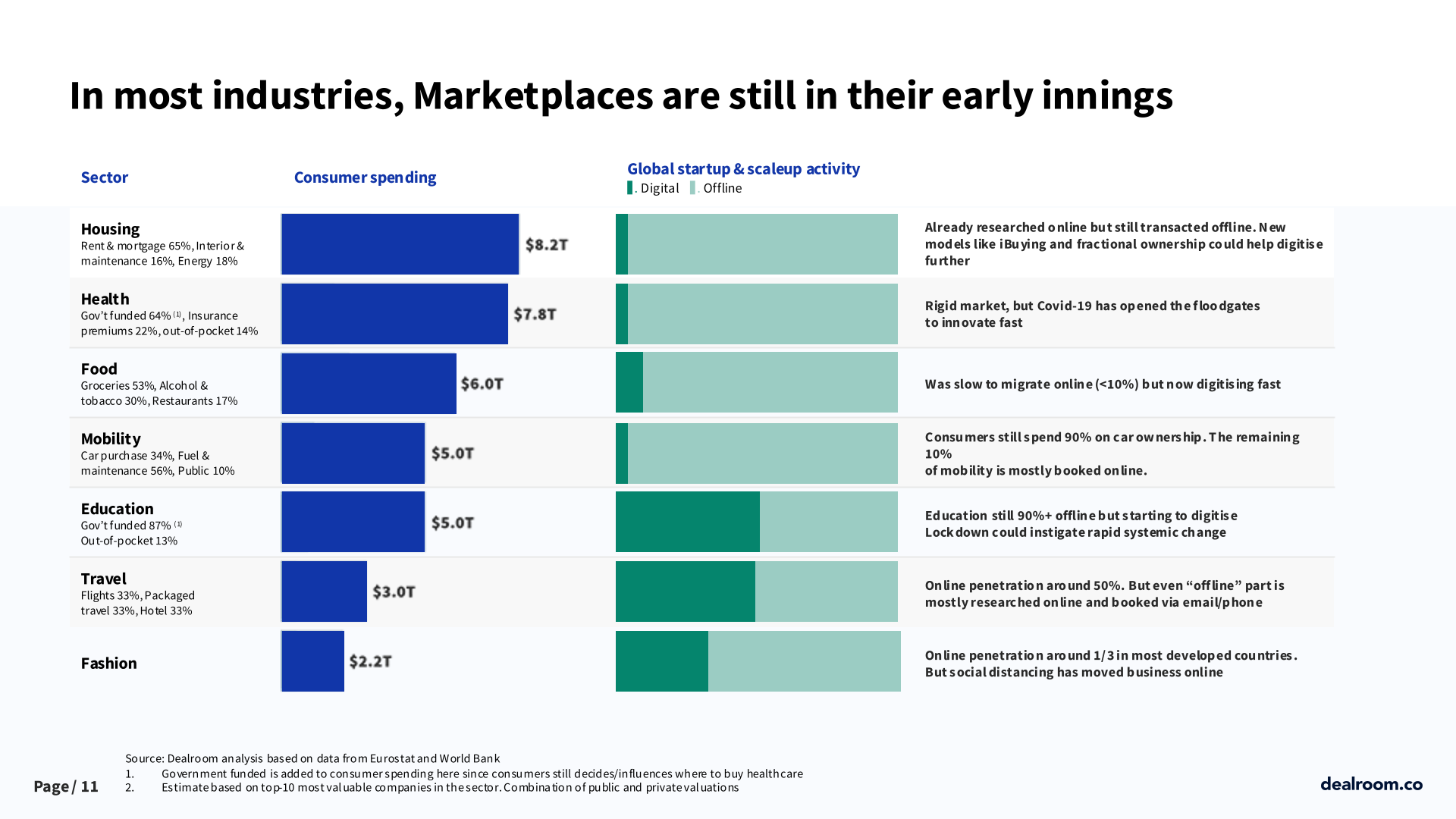
A inovação abre margem para criação de conteúdos audiovisuais extremamente realistas totalmente por IA. Conforme os dados de benchmark divulgados na página do modelo no GitHub, o Goku-T2V tem uma média de desempenho superior a vários outros modelos similares, inclusive o Sora, da OpenAI.
O benchmark está na imagem do post. Link para o Github do projeto.
Goku vs Sora