✅ POC com AWS Bedrock [Parte 2]
Caso você tenha perdido, a parte um com a performance dos modelos está aqui: https://lnkd.in/dKnTEwTK
Rápida (re)contextualização: conduzi um projeto de classificação de notícias em um veículo de imprensa. Estas notícias foram (re)classificadas de acordo com novas categorias criadas pela empresa. O objetivo era verificar a performance de leitura e conversão por categoria, criando assim, insumo analítico para as equipes editoriais.
Neste post irei falar um pouco sobre a Arquitetura e o Preço da solução. Então vamos direto aos fatos:
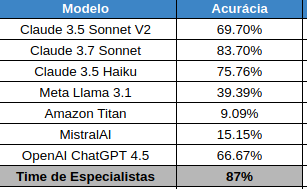
– Quem classifica cada notícia/documento é o modelo LLM escolhido dentro da plataforma AWS Bedrock. Testamos a performance de diversos modelos em nosso projeto (resultados no post anterior)
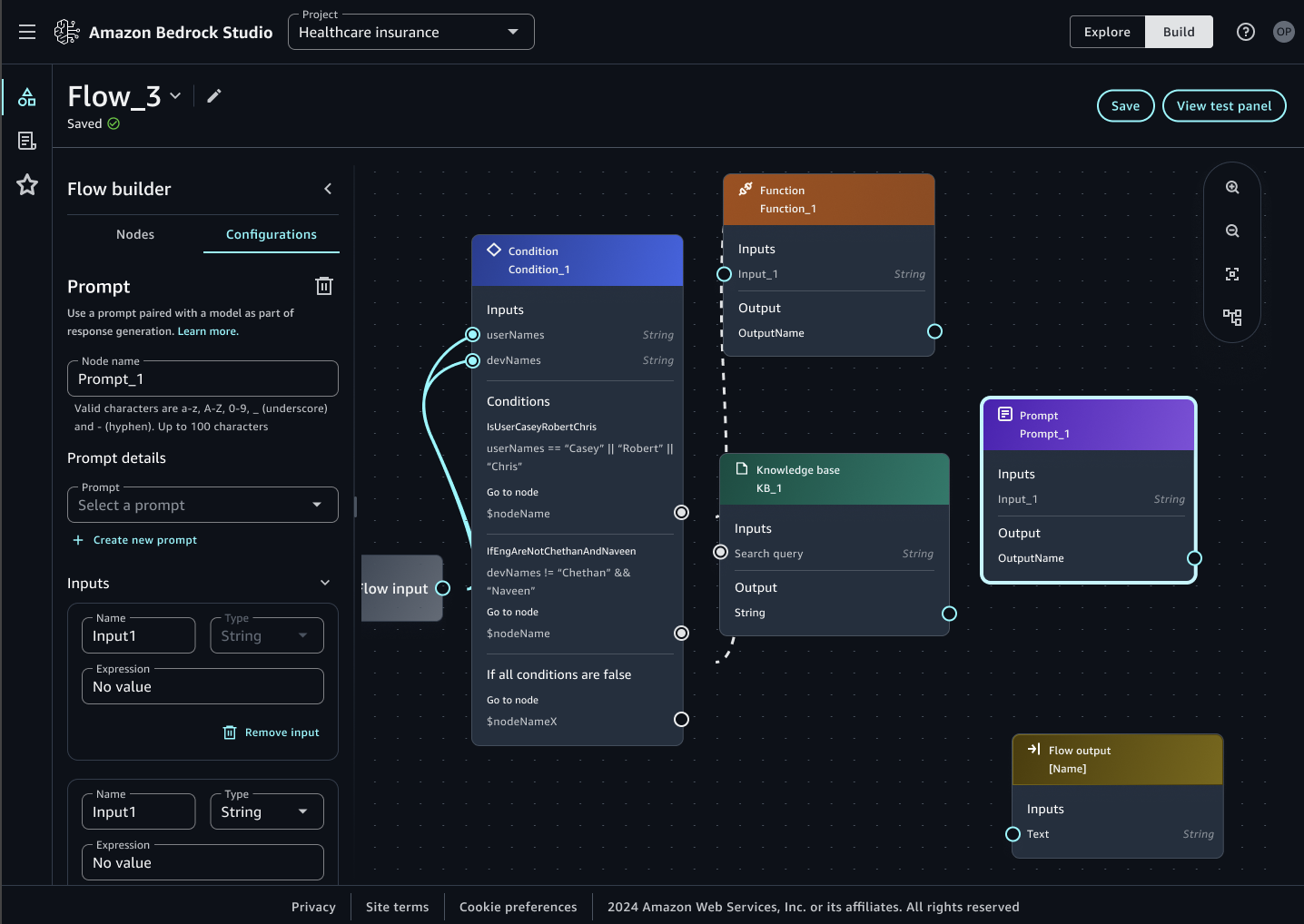
– É preciso classificar o documento e salvar o output de cada classificação. Isso foi feito utilizando-se o AWS Bedrock Flow
– É preciso orquestrar a chamada do Bedrock Flow para cada documento/notícia escolhidos para entrarem no projeto. Para isto foi utilizado uma combinação de AWS Step Functions e AWS Lambda, que itera entre todos os conteúdos salvos previamente no S3, chamando o Bedrock Flow para cada documento individualmente
– Para cada documento classificado, foi salvo um arquivo csv com o resultado no S3. Foi criado um AWS Glue Crawler que criou o Data Catalog dos resultados que depois foram disponibilizados para a equipe de Analytics através do AWS Athena
E quanto custa tudo isso?
Bom, cada ferramenta possui uma maneira de cobrar, então vamos lá:
– Cada modelo de LLM possui um preço único com uma cobrança padrão por mil tokens de entrada. Cada documento nosso possui, em médio, dois mil tokens. Escolhemos o Claude Sonnet 3.7 que cobra cerca de R$0,02 por mil tokens de entrada, portanto em nosso caso o custo foi de R$0,04 por documento classificado
– O Bedrock Flow cobra por transições dentro do workflow. São cerca de R$0,20 por 1.000 transições. Cada documento usou apenas 5 transições.
– Em relação ao AWS Lambda, ficamos dentro do free tier, que é bem generoso de um milhão de execuções, mas caso tivéssemos passado, ele custa cerca de R$1,12 por um milhão de execuções, bem barato
– Por fim, o Step Functions possui um free tier de 4 mil transições de estado. Cada documento usou apenas 2 transições, então ficou dentro do free tier também, mas caso fossemos cobrados, seria cerca de R$0,15 por mil transições de estado no workflow
Portanto, em termos de ferramental, gastamos cerca de R$45 para processar cerca de mil documentos (mais barato do que muito PF por aí).
Também processamos tudo em cerca de 1 hora, pois adicionamos paralelismo no Step Functions. A título de comparação, um humano levaria cerca de 17 horas para realizar a mesma função. Ou seja, cerca de 2 dias úteis.